“It should be no surprise that many Hadoop (big data) systems sit side by side with data warehouses. These systems serve different purposes and complement one another.”
– Joint quote from CTO of cloudera and General Manager at Teradata
As you may have heard, big data is all the craze and at the top of the technology hype cycle! In my opinion, it is thoroughly confusing business execs, overwhelming IT teams and being used to market a massive range of new startups, sometimes justifiably. The reality is that big data will most likely NOT replace your data warehouse and the data scientist will most likely NOT replace your business analyst teams.
In a recent white paper, Hadoop and the Data Warehouse: When to Use Which, two executives of leading companies in data warehousing (Teradata) and big data (cloudera) finally offer a cogent roadmap for how these are complementary technologies and how to avoid making catastrophic mistakes in your data infrastructure plans by listening to the current market hype.
Highlights
1) Even the practitioners are confused! Many of them have only strong exposure to either data warehousing or big data, but not both! This is similar to two other cultural shifts I have witnessed in the past 25 years- statisticians in the 1990’s that often didn’t understand why business intelligence was important and BI teams in the late 2000’s that often didn’t understand why self-service analytics (QlikView, Spotfire, SAS Enterprise Guide, JMP and Tableau) were so important.
“As with all technology innovation, hype is rampant, and non-practitioners are easily overwhelmed by diverse opinions. Even active practitioners miss the point, claiming for example that Hadoop replaces relational databases and is becoming the new data warehouse.”
2) Don’t throw away your Informatica, DataStage or SAS data management extract, transform and load infrastructure just yet!
“Note that Hadoop is not an Extract-Transform-Load (ETL) tool. It is a platform that supports running ETL processes in parallel. The data integration vendors do not compete with Hadoop; rather, Hadoop is another channel for use of their data transformation modules.”
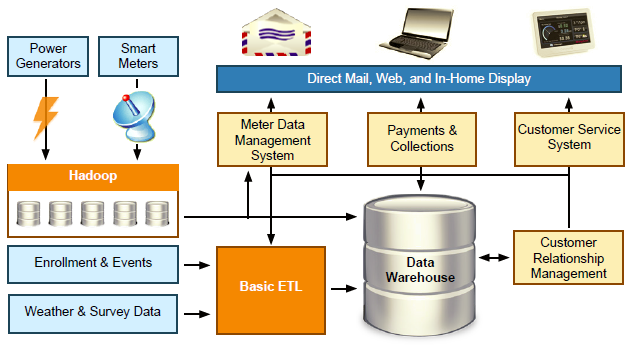
3) Hadoop is the less-expensive compliment to traditional data warehousing technologies.
“ • Hadoop is the repository and refinery for raw data.
• Hadoop is a powerful, economical and active archive.
Thus, Hadoop sits at both ends of the large scale data lifecycle — first when raw data is born, and finally when data is retiring, but is still occasionally needed.”
4) They offer a simple reference to help you select the appropriate technology, based on your project needs.
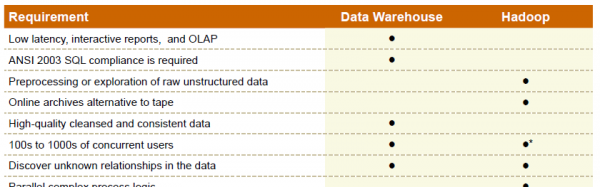
The authors close with this very simple guidance which is easy to remember. Use it as a litmus test of big data hype versus reality in your next vendor meeting:
“When it comes to Big Data, Hadoop excels in handling raw, unstructured and complex data with vast programming flexibility. Data warehouses also manage big structured data, integrating subject areas and providing interactive performance through BI tools. It is rapidly becoming a symbiotic relationship. Some differences are clear, and identifying workloads or data that runs best on one or the other will be dependent on your organization and use cases.”
Pick up the complete white paper at Teradata here or over on Cloudera here.
![]() Follow Freakalytics on Twitter
Follow Freakalytics on Twitter
 RSS for Freakalytics.com
RSS for Freakalytics.com
RSS for new course & webinar alerts
Subscribe to our newsletter